
In this article, I will try to explain how we deal with high concurrency in Teradisk. First, we will try to clarify what “concurrency” means and why is so important as a metric. Usually, we find that customers don’t understand quite well this term and its implication in their businesses.
What does concurrency mean in ecommerce and why it is so important for business?
The simplest way to explain concurrency is: *How many users should your infrastructure withstand accessing at a same time? What would be the peak number? * The answer for this question will have a great impact on the design of your infrastructure.
For instance, and taking into account the [magento official recommendations] (https://devdocs.magento.com/guides/v2.3/performance-best-practices/hardware.html) about compute sizing, it would be very different in terms of resources a platform design for 10 concurrent users versus 500 users requesting at a same time.
Strategies for dealing with high concurrency sites
They key strategy for dealing with high concurrency is **distribution**:
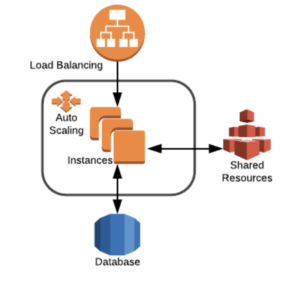
Design your infrastructure and your app capable to be deployed and served among servers. With this approach, you will solve 2 main issues: You will be able to scale horizontally and you will be one step ahead of removing single point of failure (SPF) using redundancy.
Use shared services (EFS, NFS, SoftNas) for shared resources like static content but be aware that highly accessed files (as code) should be avoided. This will imply that, in some way, you should implement a deploy system capable of deploying, simultaneously to all webservers.
An important (but sometimes underestimated) strategy is campaign planification. Planning the sending of emails in slots or batches can save your company a lot of money in terms of reducing compute resources.
But sometimes, planification is not enough and customers are in need for a dynamical response of the resources. In this case, infrastructure design can leverage the use of autoscaling. Autoscaling features of Public Clouds are great, but there are some requirements that shall be considered:
- Code and infrastructure shall be designed to be automatically assigned to a new server in case of scale out (each deploy, an artifact with code should be stored in some way and pushed to the new server). Another way is the creation of “Golden Images” for each deploy.
- Autoscaling is not instantaneous. Metrics that triggers the scale out process should be taken with care. For instance, as we saw in previous points, there is a strong correlation between CPU cores and users (or php processes). But scaling out when the deployed instances reach their maximum load would be dangerous. Metric margins should be analyzed in order to have time to spin new instances and avoid crashes. Furthermore, a hysteresis control should be implemented to avoid infinite loops of registering and unregistering instances.


