
En este artículo, intentaré explicar cómo gestionamos la alta concurrencia en Teradisk. En primer lugar, intentaremos aclarar qué significa «concurrencia» y por qué es tan importante como métrica. Normalmente, nos encontramos con que los clientes no entienden muy bien este término y su implicación en sus negocios.
¿Qué significa la concurrencia en el comercio electrónico y por qué es tan importante para las empresas?
La forma más sencilla de explicar la concurrencia es: *¿Cuántos usuarios debería soportar tu infraestructura accediendo al mismo tiempo? ¿Cuál sería el número máximo? * La respuesta a esta pregunta tendrá un gran impacto en el diseño de tu infraestructura.
Por ejemplo, y teniendo en cuenta las [magento official recommendations] sobre el dimensionamiento computacional, sería muy diferente en términos de recursos el diseño de una plataforma para 10 usuarios concurrentes frente a 500 usuarios solicitando al mismo tiempo.
Estrategias de gestión de sitios de alta concurrencia
La estrategia clave para hacer frente a la alta concurrencia es la **distribución**:
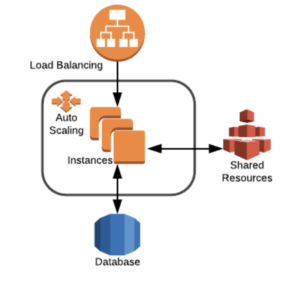
Diseña tu infraestructura y tu aplicación con capacidad para ser desplegada y servida entre servidores. Con este enfoque, resolverás 2 problemas principales: Podrás escalar horizontalmente y estarás un paso por delante de eliminar el punto único de fallo (SPF) usando redundancia.
Utiliza servicios compartidos (EFS, NFS, SoftNas) para los recursos compartidos como el contenido estático, pero ten en cuenta que deben evitarse los archivos a los que se accede mucho (como el código). Esto implicará que, de alguna manera, deberás implementar un sistema de despliegue capaz de desplegar, simultáneamente a todos los servidores web.
Una estrategia importante (pero a veces subestimada) es la planificación de campañas. Planificar el envío de correos electrónicos en franjas horarias o lotes puede ahorrar a su empresa mucho dinero en términos de reducción de recursos informáticos.
Pero a veces, la planificación no es suficiente y los clientes necesitan una respuesta dinámica de los recursos. En este caso, el diseño de la infraestructura puede aprovechar el uso del autoescalado. Las funciones de autoescalado de las nubes públicas son estupendas, pero hay algunos requisitos que deben tenerse en cuenta:
El código y la infraestructura deben ser diseñados para ser asignados automáticamente a un nuevo servidor en caso de scale out (cada deploy, un artefacto con código debe ser almacenado de alguna manera y empujado al nuevo servidor). Otra forma es la creación de «imágenes doradas» para cada despliegue.
- El autoescalado no es instantáneo. Las métricas que disparan el proceso de escalado deben ser tomadas con cuidado. Por ejemplo, como vimos en puntos anteriores, existe una fuerte correlación entre los núcleos de CPU y los usuarios (o procesos php). Pero escalar cuando las instancias desplegadas alcanzan su carga máxima sería peligroso. Se deben analizar los márgenes métricos para tener tiempo de girar nuevas instancias y evitar caídas. Además, se debería implementar un control de histéresis para evitar bucles infinitos de alta y baja de instancias.
